Paper Review 2: Deep Residual Learning for Image Recognition (ResNet)
Trigger
Degradation Problem → When layers are added, the performance of network is degraded
Motivation
- 추가된 Layer가 identity면 이전꺼보다 안 구려짐 → 그럼 identity가 더 optimal하네?
- 그럼 identity를 base로 삼아서 최적화 수행하면 최소한 identity만큼은 될테니 더 쉬워지겠네
- H(x) 를 학습시킬 수 있다면 H(x) - x 도 학습시킬 수 있겠군
- H(x) 대신에 F(x) = H(x) - x 를 학습하자!
Idea
- 파라미터가 원래 feature와의 잔차만 배우게끔 하자!
Residual Building Blocks
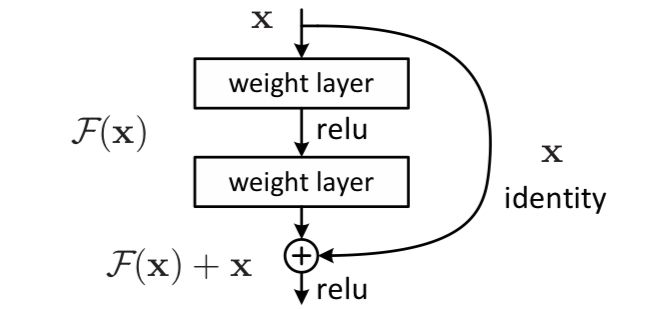
구현 코드
https://github.com/pytorch/vision/blob/6db1569c89094cf23f3bc41f79275c45e9fcb3f3/torchvision/models/resnet.py#L124
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
장점
- 최적화가 더 쉬워짐 + 더 성능이 좋아짐
작동 잘하는 이유
- Reduced Vanishing Gradient → Depth without Degradation