Paper Review 5: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (MobileNetV1)
Summary
- Depthwise separable convolutions → Reduced Computational cost dramatically
- Introduced 2 simple global hyperparameters that trade off latency and accuracy
- Width Multiplier
- Resolution Multiplier
1. Motivation
Current advances to improve accuracy don’t consider “efficiency” of the network → size and speed
2. MobileNet Architecture
2-1. Idea
Starts from the effects of standard convolution
- filtering features based on conv kernels
- combining features to produce new representation
→ Then, could we split these into two steps?
2-2. Depthwise Separable Convolution
How to do this
- Depthwise Conv: Apply single filter per each input channel
- Pointwise Conv: 1x1 convolution, creates a linear combination of output of depthwise layer
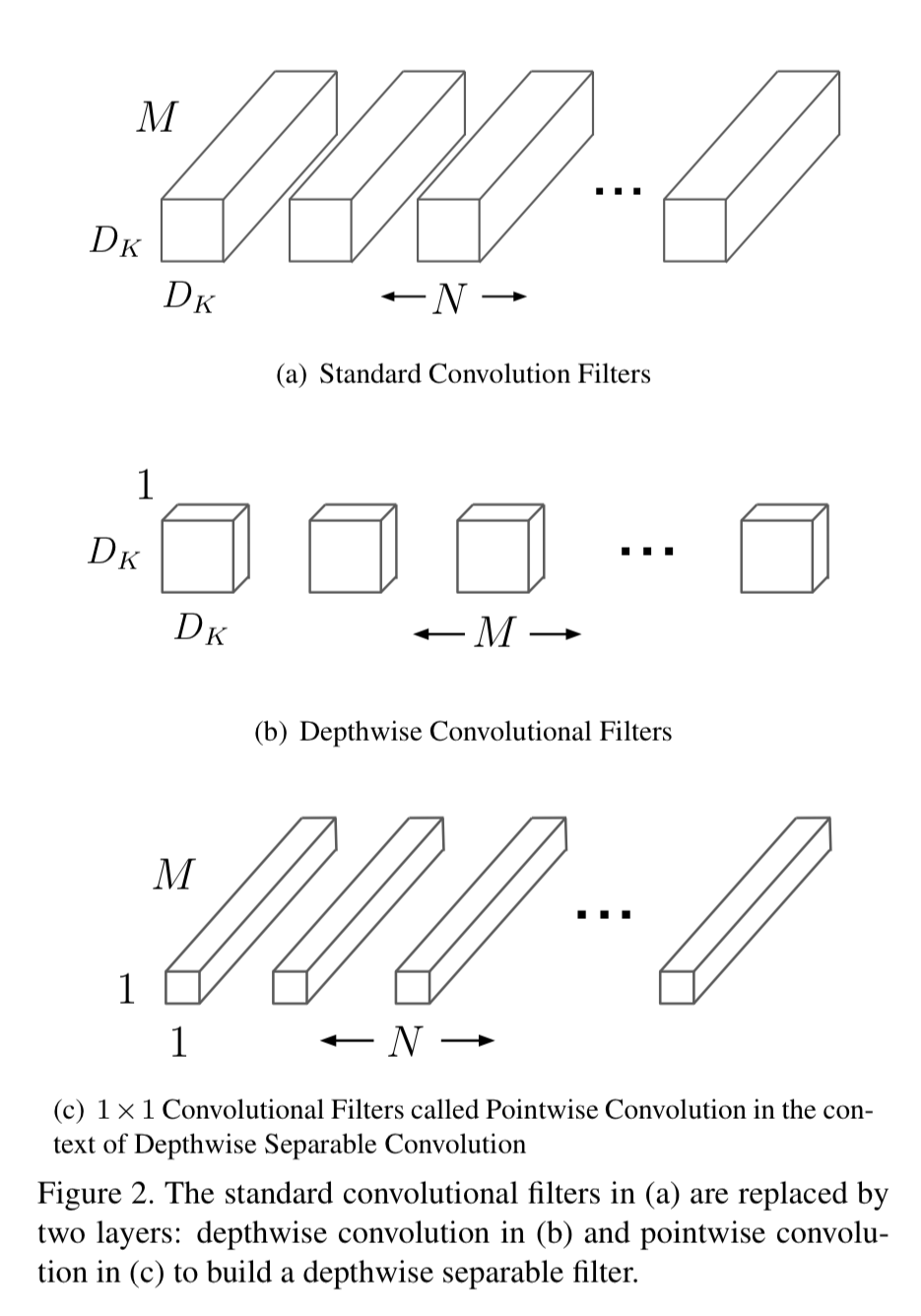
Standard Convolution Computational Cost
- D_K: kernel size / M: # of output features / N: # of input features / D_F: input feature map size
Depthwise Separable Convolution Computational Cost
\[D_K · D_K · M · D_F · D_F + M · N · D_F · D_F\]Reduction in Computation
\[\frac{1}{N} + \frac{1}{D_K^2}\]Question)
- Why computational cost are computed with D_F not the output feature map size D_G?
- Is it because BIG-O notation? which considers worst time complexity? But what if D_G > D_K ?
- In this paper, the hypothesis was D_G = D_F. (padding = 1, stride = 1.. maybe same padding?)
3. Global Hyperparameters
Consider these hyperparameters that trades off accuracy and speed. Experiment with these hyperparameters and then choose the best model that you can get.
3-1. Width Multiplier (ɑ)
- Thin a network uniformly at each layer
- Computational cost reduces quadratically (ɑ^2) \(D_K·D_K·ɑM·D_F·D_F+ɑM·ɑN·D_F·D_F\)
3-2. Resolution Multiplier (𝜌)
- Apply to input image and to internal representation of every layer by the same multiplier
- Computational cost reduces by 𝜌^2 \(D_K·D_K·ɑM·𝜌D_F·𝜌D_F+ɑM·ɑN·𝜌D_F·𝜌D_F\)
3-3. Why two above rather than reducing the depth of layers?
Because thinner network has better performance than shallower network