Paper Review 10: Rich feature hierarchies for accurate object detection and semantic segmentation (R-CNN)
Extract region proposals and compute CNN features, then classify regions
- Can use various pre-trained CNN architectures + domain-specific fine-tuning
Architecture
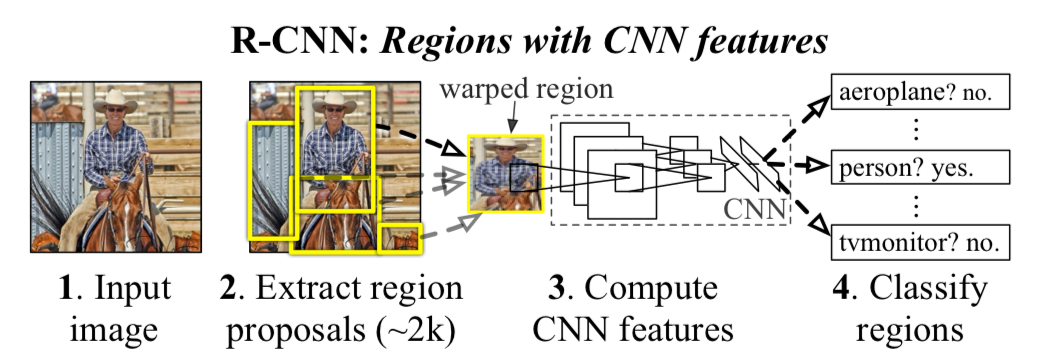
- Takes an input image
- Extracts around 2000 region proposals (used Selective Search Algorithm)
- Computes features for each proposal using CNN
- Classifies each region using class-specific linear SVMs
In this paper…
Input → Selective Search → AlexNet → SVMs
Objective Function (Bounding Box Regression)
Goal: learn transformation that maps proposed box P to ground-truth box G
Training pair: (P, G)
\[P^i=(P_x^i, P_y^i, P_w^i, P_h^i) \\ G^i = (G_x^i, G_y^i, G_w^i, G_h^i)\]Parameterize transformation
\[d_x(P),\ d_y(P),\ d_w(P),\ d_h(P)\]- d_x, d_y → scale-invariant translation of the center of P’s bounding box
- d_w, d_h → log-space translations of width and height of P’s bounding box
After learning those functions, → Transform an input proposal P into predicted ground-truth box G_hat
\[\hat{G_x}=P_w d_x(P)+P_x \\ \hat{G_y}=P_h d_y(P)+P_y \\ \hat{G_w}=P_w \exp(d_w(P)) \\ \hat{G_h}=P_h \exp(d_h(P))\]Each d(P) is modeled as linear function of features of proposal P, (ϕ)
\[d_★(P)=w_*^{\mathsf{T}}ϕ(P)\]Learn W★ by optimizing regularized least squares objective function (ridge regression)
\[W_*=\argmin_{\hat{w_*}}\sum_i^N(t_*^i-\hat{w_*^\intercal}ϕ(P^i))^2+λ||\hat{w_*}||^2\]Regression target t_* are defined as
\[t_x=(G_x-P_x)/P_w\\ t_y=(G_y-P_y)/P_h\\ t_w=\log(G_w/P_w)\\ t_h=\log(G_h/P_h)\]