Summary
- YOLOv2 = Adds several techniques to YOLOv1
- YOLO9000 = Uses WordTree for semi zero-shot detection
YOLOV2
- Batch Normalization
- High Resolution Classifier
- First fine-tune classification network with ImageNet
- Fine-tune resulting network on detection
-
Conv with Anchor boxes
Removed FC layers from v1 and use anchor boxes
-
Dimension Clusters
Instead of choosing anchor boxes by hand, use k-means clustering on the training set bounding boxes.
K-means clustering? = grouping into k similar clusters by distance
How does this paper define distance metric? → want to make good IOU scores which is independent of the box size
\[d(\text{box},\ \text{centroid})=1-\text{IOU}(\text{box},\ \text{centroid})\]Why does this lead to good results? → Because it starts the model off with a better representation, it makes task easier to learn
-
Direct location prediction
When using anchor boxes, model became unstable because any anchor box can end up at any point in the image, regardless of what location predicted the box
\[x = (t_x*w_a)-x_a\\ y = (t_y*h_a) - y_a\]Solution → Predict location coordinates relative to location of grid cell
Network predicts bounding box (5 t’s) grid cell’s location offset (cx, cy) Bounding box prior width, height (pw, ph)
\[b_x=σ(t_x)+c_x\\ b_y=σ(t_y)+c_y\\ b_w=p_we^{t_w}\\ b_h=p_he^{t_h}\\ Pr(\text{object})*\text{IOU}(b,\text{object})=σ(t_o)\] -
Fine-Grained Features (Passthrough Layer)
Implemented passthrough layer that concatenates higher resolution features with low resolution features.
-
Multi-Scale Training
Non-fixed input image size
-
Darknet-19
Changed VGG models to learn faster. 3x3 filters / doubled # of channels / 1x1 filters for compressing / batch normalization …
YOLO9000
Motivation
- Data is scarce so that it is hard to scale detection model → Harness existing classification data and use it to expand the scope of detection systems
Idea
Joint training on both detection and classification data
- Detection data → Full backpropagation
- Classification data → Partial backpropagation only for classification specific parts
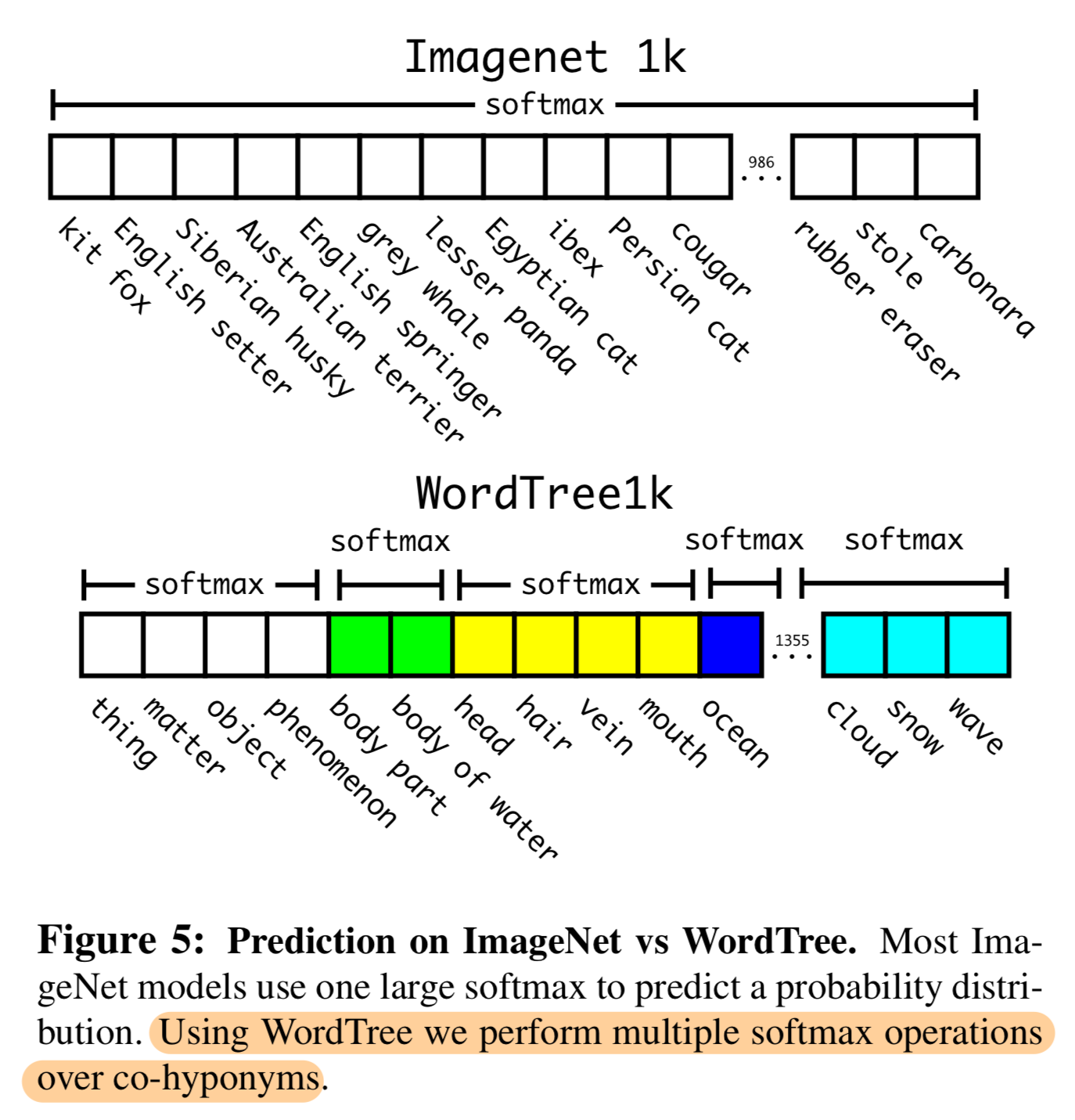
How to jointly train? → Hierarchical classification
- Make WordTree with WordNet
-
Dataset combination with WordTree
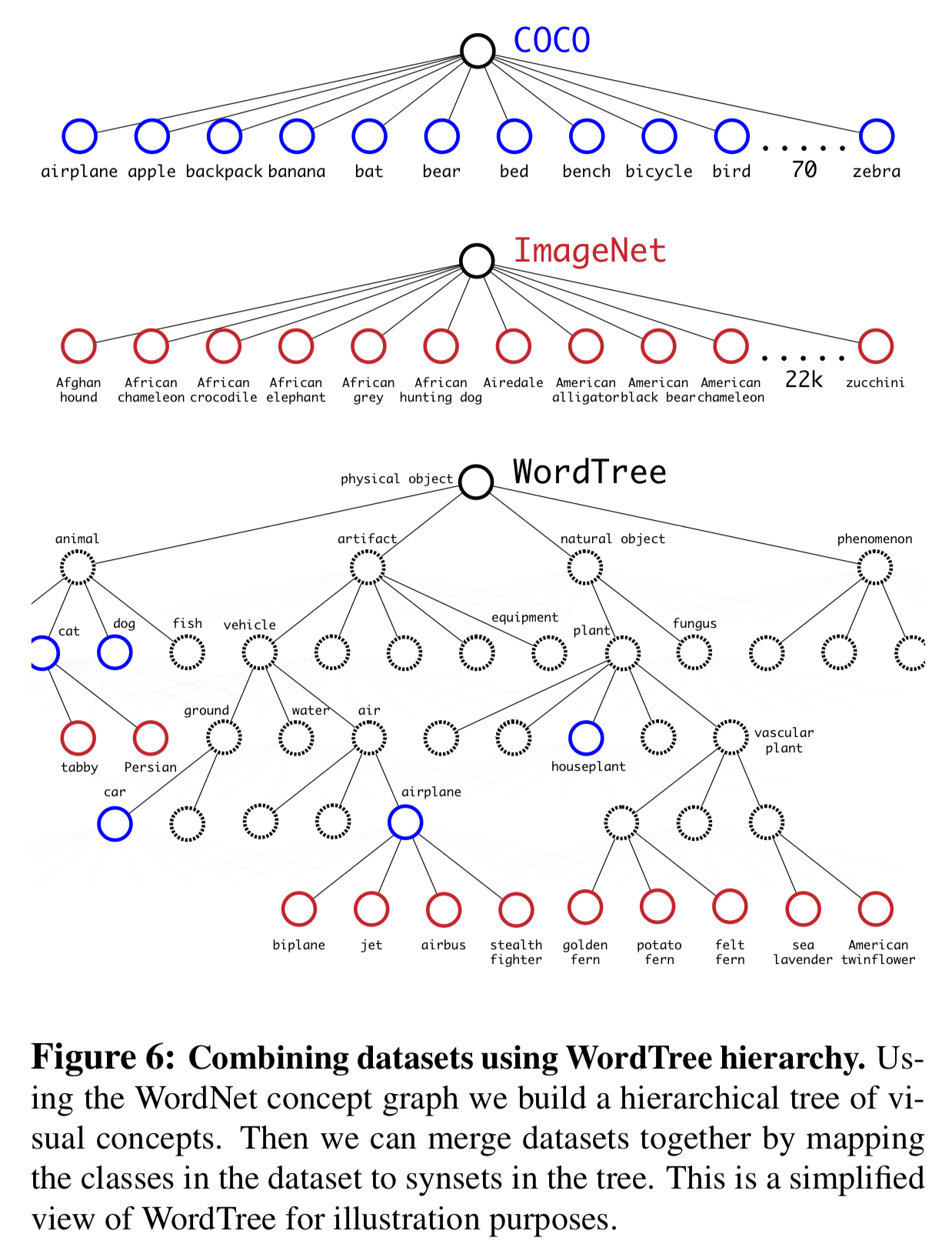
- Perform classification with WordTree → Predict conditional probabilities at every node for probability of each hyponym of that synset given that synset

|
|