Paper Review 23: Linguistic Regularities in Continuous Space Word Representations
Summary
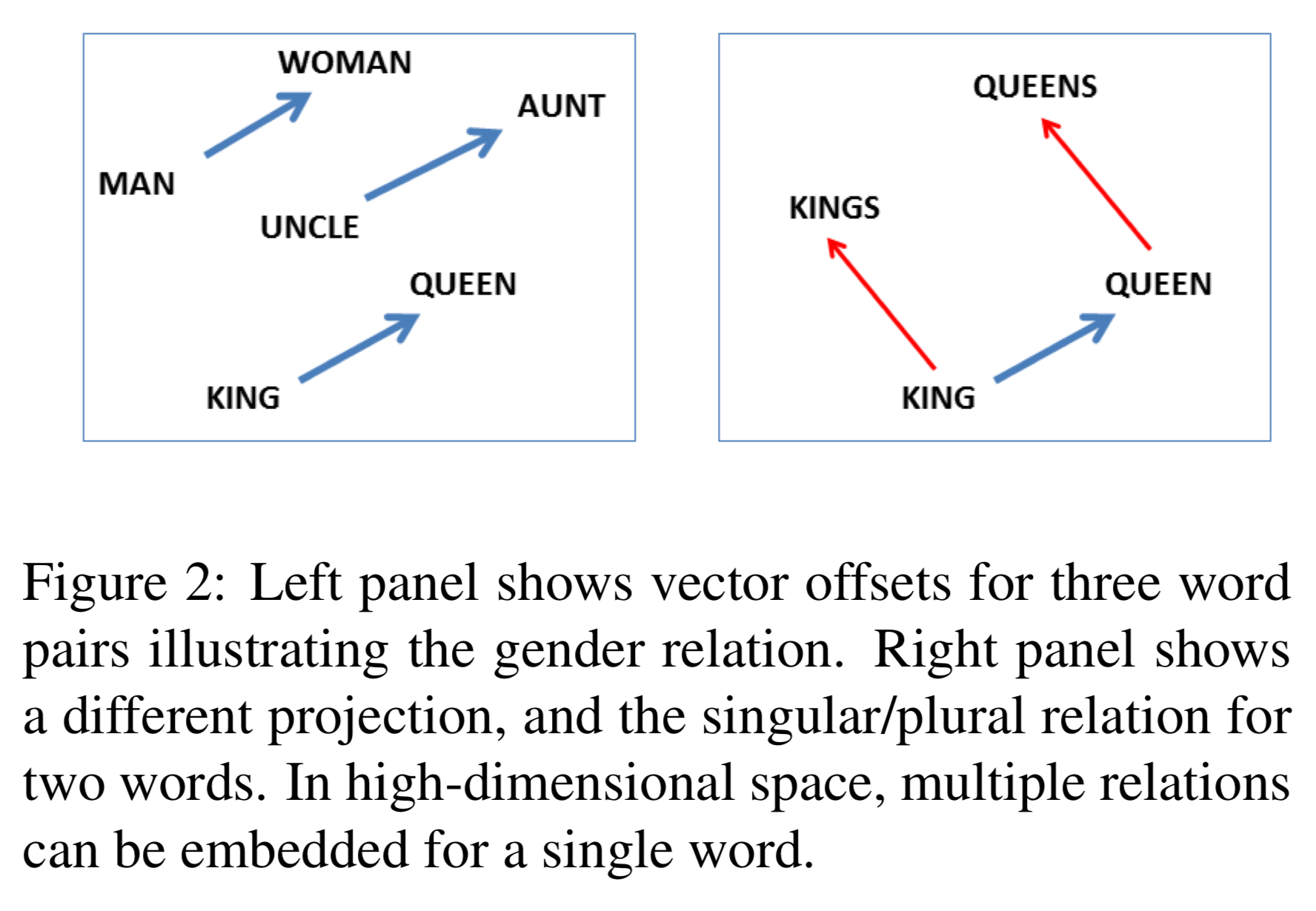
Constant vector offsets between pairs of words shares a particular relationship!
- EX: apple - apples ≈ family - families
Method to verify
Assuming relationships between vectors, perform the test below to verify.
- Train a traditional RNN model to get word representations
-
Create a test set of analogy questions of the form “as is to be as c is to ___”
We need 2 kind of test sets.
- Syntactic test set
- Semantic test set
- Use embedding vectors to answer the question, “a:b - c:d” where d is unknown
- Find embedding vectors $x_a$, $x_b$, $x_c$
- compute $y = x_b-x_a+x_c$
-
Find the word whose embedding vector has the greatest cosine similarity to y
\[w^*=\argmax_w\frac{x_wy}{||x_w||\ ||y||}\]
Results
- Almost 40% accuracy
- Outperforms existing model at that time with SemEval-2012 Task 2 questions
Thoughts
Is it possible to say that the hypothesis of word representations has been validated with a model with 40% accuracy although it outperformed the previous model at that time?
I thought that it should be tested much more thoroughly