Summary
The Bag-of-Words and Skip-gram models significantly reduce the computational cost of training word representations while maintaining or improving accuracy. This enables their use in larger datasets and vocabularies, pushing the boundaries of what is possible with word vector representations.
1. Previous Models
1-1. NNLM (Feedforward Neural Net Language Model)
At the input layer, N previous words are encoded using 1-of-V coding, where V is the size of the vocabulary. Input layer is projected to a projection layer P that has dimensionality N x D. H is the hidden layer size. V is a resulting output layer.
Computational complexity per each training example is
\[Q = N \times D + N \times D \times H + H \times V,\]1-2. RNNLM (Recurrent Neural Net Language Model)
\[Q = H \times H + H \times V\]H x V can be efficiently reduced to $H \times \log_2V$ by using hierarchical softmax.
2. New Log-linear Models
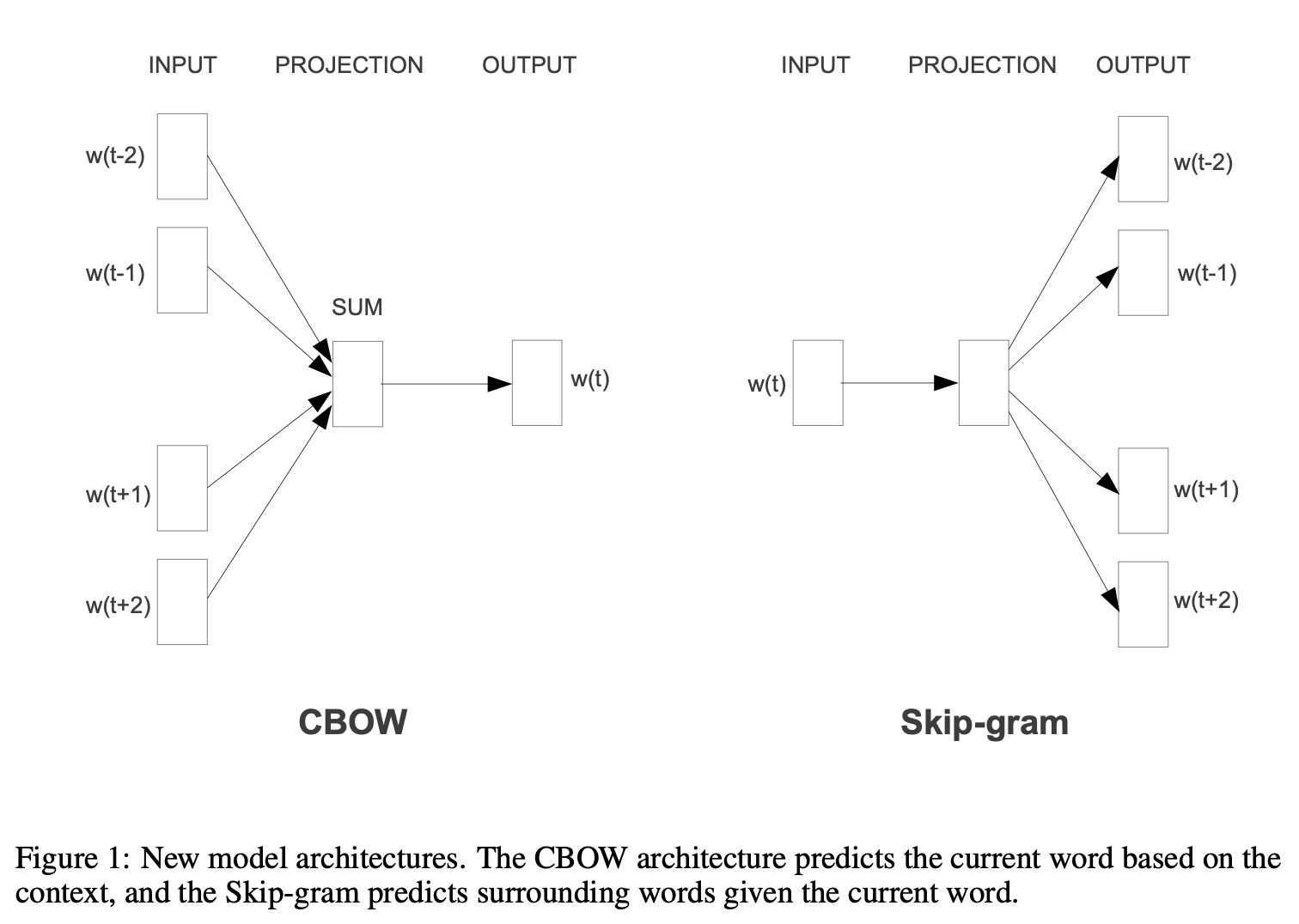
2-1. CBOW Model (Continuous Bag-of-Words Model)
Predicts a word based on its context (surrounding words), ignoring word order. It averages the vectors of surrounding words to predict the target word, which makes it computationally efficient.
\[Q= N \times D + D \times \log_2V\]2-2. Skip-gram Model
This model does the reverse of CBOW. It uses the current word to predict surrounding words. It maximizes the classification of context words within a certain range around the input word. Skip-gram is particularly good at capturing semantic relationships between words.
\[Q= C \times (D+D \log_2V)\]where C is the maximum distance of the words.
2-3. Why above 2 models are faster than traditional model?
- Using hierarchical softmax → computational cost reduced to log
- No hidden layer dense matrix multiplication → Reduced computation
- AS-IS: Embedding Matrix → Hidden Layer → output
- TO-BE: Embedding Matrix → Hierarchical Softmax → output
3. Advantages:
- Both models are simpler and more computationally efficient than previous neural network-based models (like feedforward and recurrent neural network language models)
- They can be trained on massive datasets containing billions of words, significantly improving performance on NLP tasks such as word similarity and analogy tasks
- Efficient when using parallel training on large datasets
4. Results:
- The paper reports state-of-the-art performance on a new test set that measures syntactic and semantic word relationships.
- Experiments show that the Skip-gram model performs particularly well on semantic tasks, while the CBOW model is slightly better at syntactic tasks.