Paper Review: Sequence to sequence learning with neural networks
Summary
Showed LSTM architecture that can solve general sequence to sequence problems
- One LSTM to read input sequence → Fixed dimensional vector representation
- Another LSTM to extract output sequence from that vector
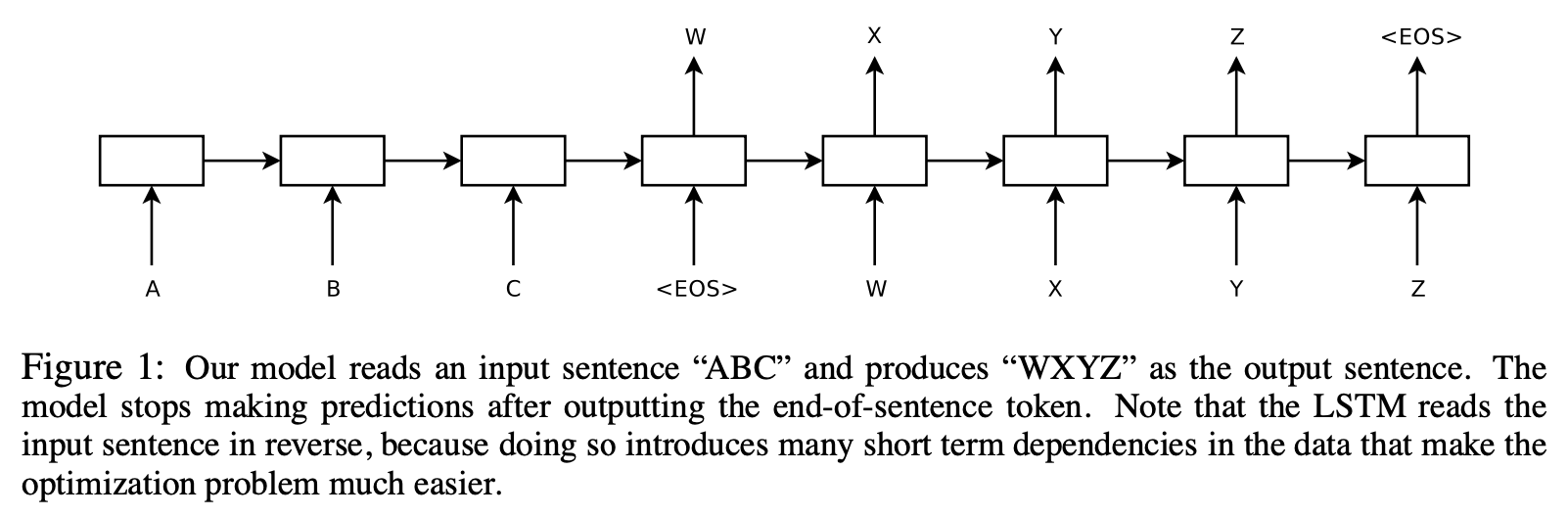
Training
Decoding and Rescoring
Training objective is to maximize the log probability of a correct translation T given the source sentence S where $\mathcal{S}$ is the training set.
\[1/|\mathcal{S}|\sum_{(T,S)\in \mathcal{S}} \log p(T|S)\]After training, we can produce translations by finding the most likely translation according to LSTM
\[\hat{T}=\arg \max_T p(T|S)\]Search for the most likely translation using a simple left-to-right beam search decoder maintaining B partial hypotheses
Reversing the Source Sentences
LSTM learned much better when the source sentences are reversed while the target sentence is not reversed
Why?) “Minimal time lag” → average distance between corresponding words in the source and the target is unchanged